- Роль
- Архитектор и идеолог решения. Проектирование с нуля и сопровождение до промышленного внедрения.
- Стадия
- В промышленной эксплуатации. Публичная демо-ветка — pir-s.ru, AI-страница — pir-s.ru/ai.
- Стек
- React (CRA + craco) · Node/TypeScript BFF · Hasura/GraphQL · Postgres · Docker · nginx
- Слои
- client · server (BFF) · hasura · deploy · seeder / docs
- AI-домен
- ИРД: классификация, валидация XML, нормконтроль, коллизии, генерация ТЗ
Задача
Инженер-проектировщик и главный инженер проекта (ГИП) тонут в объёмах исходно-разрешительной документации, версиях, согласованиях и ручных проверках. Нужна платформа, где объект живёт в одной модели данных, а ИИ-помощник не «рисует слайды», а опирается на структурированные артефакты: реестр документов, XML-контуры, статусы разделов и воспроизводимые контракты между фронтом, BFF и аналитическим backend.
Архитектура — многослойная система в одном репозитории
client/ — React-приложение
React (CRA + craco). Исторически Apollo/GraphQL для доменных данных; новые сценарии AI/ИРД/ORD/normcontrol часто идут через REST к BFF — это удобнее для AI-экранов с разнородным контрактом и meta-полями.
server/ — Node/TypeScript BFF
Сессии и auth, внешние интеграции, хранилища, адаптация ответов Hasura, webhook/actions и демонстрационные mock-маршруты для ИИ-экранов. BFF принимает на себя сложные сценарии оркестрации и не позволяет фронту знать лишнее про данные.
hasura/ — источник истины по схеме БД
Metadata, идемпотентные SQL-миграции, демо-сид. Hasura даёт типизированный доступ к данным и снимает с команды задачу писать рутинные CRUD-эндпоинты.
deploy/ — Docker, nginx, supervisord
Контейнеры и сценарии выкладки — единый артефакт для dev/stage/prod.
seeder/ и docs/ — воспроизводимые demo-данные и контракты
Включая примеры XML ИРД и референсные analysis JSON. Контракты и спецификации лежат рядом с кодом и эволюционируют вместе с ним.
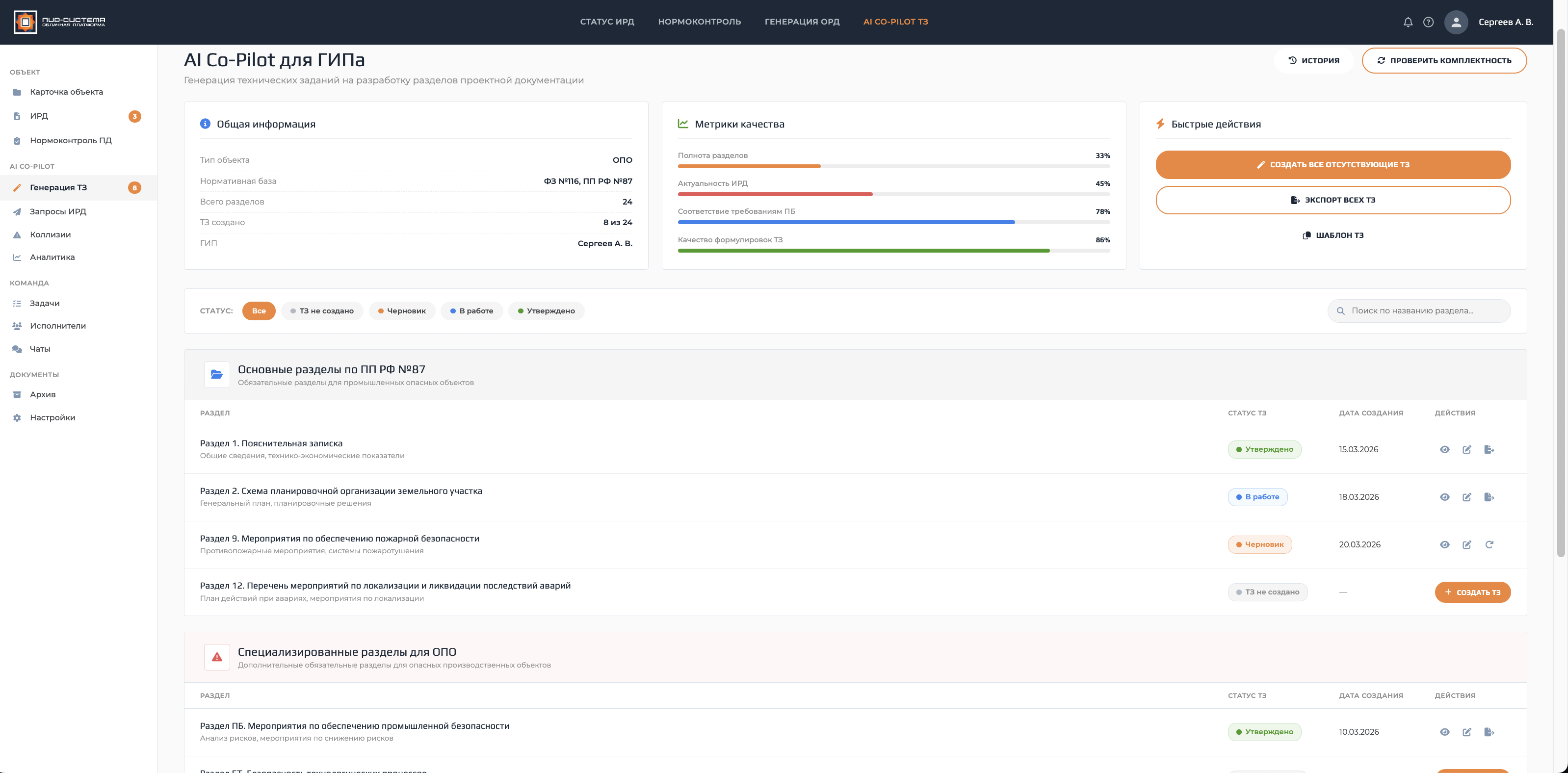
ИИ-ассистент для ГИПа
В продуктовой карте — сценарии вокруг ИРД:
- Расширенная классификация типов документов ИРД с учётом структуры реестра.
- Валидация XML в исходно-разрешительной документации.
- Модульный анализ и фрагментация под лимиты LLM — не пытаемся вместить 200-страничный PDF в одно окно контекста.
- Поиск коллизий между документами и разделами.
- Чек-листы нормконтроля — машинно-проверяемые правила, а не «свободная сверка».
- Генерация сопутствующих текстов и ТЗ на разделы проектной документации.
В демо-ветке часть тяжёлого анализа заменена контролируемыми mock-эндпоинтами и фикстурами — чтобы команда могла развивать UX и контракты без блокировки на полный ML-контур. Параллельно описан перенос зрелых артефактов из исследовательского контура ai-gip и зарезервирован слот analysis-container/ под среду выполнения Python для анализа.
Ключевые архитектурные решения
REST к BFF для AI-экранов, GraphQL/Hasura для доменных данных. Не пытаемся «всё через один протокол». GraphQL хорош для структурных запросов и фильтров над сущностями; REST к BFF — для нерегулярных AI-контрактов с meta-полями, идемпотентности и пошагового progress-API.
Демо-контур с mock-эндпоинтами вместо «всё или ничего». ИИ-экраны можно собрать и стабилизировать до того, как готов полный аналитический backend. Контракты JSON фиксированы; переезд на «живую» среду выполнения Python — это замена реализации, а не переписывание UI.
Worktree-папки для исследовательских веток (ai-gip/, mcp-server/, qdrant-config/). Они не обязательны в каждой сборке — это пространство для экспериментов, не нагружающее основной пайплайн.
Инженерная культура: документация как часть продукта
В репозитории закреплены:
- Runbook демо-сервера — как поднять, что отвалится первым, как чинить.
- Журнал «граблей» по областям (frontend, Hasura, deploy, Postgres) — формат «симптом → корневая причина → как лечить».
- Спецификации по IRD analysis для demo — какие поля что значат.
- Аудит переноса возможностей из ai-gip — что готово, что в работе.
Это снижает стоимость онбординга и позволяет агентам и людям работать точечно — по файлам маршрутов, меню, BFF-роутов и миграций — вместо раздувания одного бесконечного контекста.
Границы: честно про объём и риски
Демо-контур намеренно упрощает часть тяжёлых веток (например, обработку «живых» сканов) в пользу XML-прототипов и фикстур. Папки ai-gip/, mcp-server/, qdrant-config/ в worktree — вспомогательные и исследовательские материалы, а не обязательная среда выполнения в каждой сборке. Публичное портфолио не дублирует закрытый Git: для знакомства с продуктом ориентир — домен pir-s.ru и ветка demo по согласованию с владельцем репозитория.